
Star and Snowflake Schema
Star Schema
Dimensional modeling: star schema Fact tables
- Holds records of a metric
- Changes regularly
- Connects to dimensions via foreign keys
- Example:
- Supply books to stores in USA and Canada
- Keep track of book sales
Dimension Tables
- Holds descriptions of attributes
- Does not change as often
Star Schema Example
- One dimension
![image]()
- One dimension
Snowflake Schema (an extension)
- More than one dimension because dimension tables are normalized
![image]()
- More than one dimension because dimension tables are normalized
What is Normalization?
- Database design technique
- Divides tables into smalller tables and connects them via relationships
- Goal reduce redundancy and increase data integrity
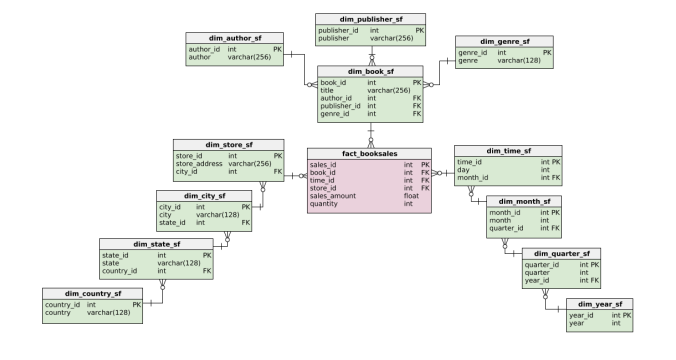
Book dimension of the star schema
![image]() Most likely to have repeating values:
Most likely to have repeating values:- Author
- Publisher
- Genre
Book dimension of the snowflake schema
![image]()

 Most likely to have repeating values:
Most likely to have repeating values: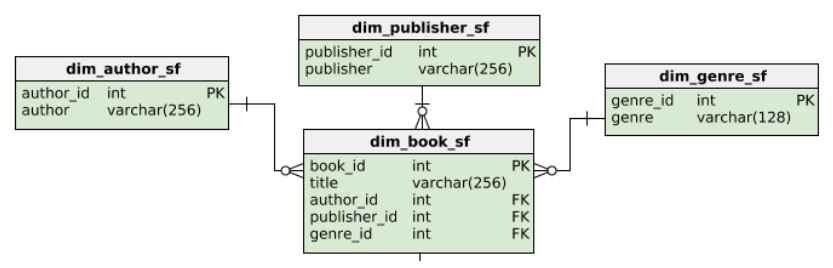
Normalized and Denormalized Databases
Back to our book store example
![image]()
Denormalized Query
Goal: get quantity of all Octavia E.Butler books sold in Vancouver in Q4 of 2018
1 2 3 4 5 6 7 8 9
SELECT SUM(quantity) FROM fact_booksales -- Join to get city INNER JOIN dim_store_star on fact_booksales.store_id = dim_store_star.store_id -- Join to get author INNER JOIN dim_book_star on fact_booksales.book_id = dim_book_star.book_id -- Join to get year and quarter INNER JOIN dim_time_star on fact_booksales.time_id = dim_time_star.time_id WHERE dim_store_star.city = 'Vancouver' AND dim_book_star.author = 'Octavia E. Butler' AND dim_time_star.year = 2018 AND dim_time_star.quarter = 4;
Normalized Query
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
SELECT SUM(fact_booksales.quantity) FROM fact_booksales -- Join to get city INNER JOIN dim_store_sf ON fact_booksales.store_id = dim_store_sf.store_id INNER JOIN dim_city ON dim_store_sf.city_id = dim_city_sf.city_id -- Join to get author INNER JOIN dim_book_sf ON fact_booksales.book_id = dim_book_sf.book_id INNER JOIN dim_author_sf ON dim_book_sf.author_id = dim_author_sf.author_id -- Join to get year and quarter INNER JOIN dim_time_sf ON fact_booksales.time_id = dim_time_sf.time_id INNER JOIN dim_month_sf ON dim_time_sf.month_id = dim_month_sf.month_id INNER JOIN dim_quarter_sf ON dim_month_sf.quarter_id = dim_quarter_sf.quarter_id INNER JOIN dim_year_sf ON dim_quarter_sf.year_id = dim_year_sf.year_id WHERE dim_city_sf.city = 'Vancouver' AND dim_author_sf.author = 'Octavia E.Butler' AND dim_year_sf.year = 2018 AND dim_quarter_sf.quarter = 4;
Why Normalization?
- Normalization saves space as it eliminates data redundancy
- Normalization ensures better data integrity
- Enforces data consistency: Must respect naming conventions because of referential integrity, e.g:- ‘California’, not ‘CA’ or ‘california’
- Safer updating, removing, and inserting: Less data redundancy = less records to alter
- Easier to redesign by extending: Smaller tables are easier to extend than larger tables
Disadvantage of Normalization
- Complex queries require more CPU

Normal Forms
Normalization
Idenfity repeating groups of data and create new tables for them
A more formal definition:
The goals of normalization are to:- Be able to characterize the level of redundancy in a relational schema
- Provide mechanisms for transforming schemas in order to remove redundancy
Ordered from least to most normalized:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Elementary Key Normal Form (EKNF)
- Boyce-Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
- Essential Tuple Normal Form (ETNF)
- Fifth Normal Form (5NF)
- Domain-Key Normal Form (DKNF)
- Sixth Normal Form (6NF)
1NF Rules
- Each record must be unique - no duplicate rows
- Each cell must hold one value
2NF
- Must satisfy 1NF AND
- If primary key is one column
- then automatically satisfies 2NF
- If there is a composite primary key
- then each non-key column must be dependent on all the keys
- If primary key is one column
- Must satisfy 1NF AND
3NF
- Satisifes 2NF
- No transitive dependencies: non-key columns can’t depend on other non-key columns
Data Anomalies
What is risked if we don’t normalize enough?
- Update anomaly
- Insertion anomaly
- Deletion anomaly
The more normalized the database, the less prone it will be to data anomalies
Update Anomaly
Data inconsistency caused by data redundancy when updating
![image]()
To update student
520s email:- Need to update more than one record, otherwise, there will be inconsistency
- User updating needs to know about redundancy
Insertion Anomaly
Unable toadd a record due to missing atributes
![image]()
Unable to insert a student who has signed up but not enrolled in any courses
Deletion Anomaly
Deletion of record(s) causes unintentional loss of data
![image]()
If we delete Student
230, what happens to the data onCleaning Data in R?
